Standard Converters
These are the standard converters that exist in a default installation. For writing and applying custom converters, see below.
Directory Converter
The Directory Converter creates StructureElements for each File and Directory inside the current Directory. You can match a regular expression against the directory name using the ‘match’ key.
Simple File Converter
The Simple File Converter does not create any children and is usually used if a file shall be used as it is and be inserted and referenced by other entities.
Markdown File Converter
Reads a YAML header from Markdown files (if such a header exists) and creates children elements according to the structure of the header.
DictElement Converter
DictElement → StructureElement
Creates a child StructureElement for each key in the dictionary.
Typical Subtree converters
The following StructureElement types are typically created by the DictElement converter:
BooleanElement
FloatElement
TextElement
IntegerElement
ListElement
DictElement
Note that you may use TextElement for anything that exists in a text format that can be
interpreted by the server, such as date and datetime strings in ISO-8601 format.
Scalar Value Converters
BooleanElementConverter, FloatElementConverter, TextElementConverter, and IntegerElementConverter behave very similarly.
These converters expect match_name and match_value in their definition which allow to match the key and the value, respectively.
Note that there are defaults for accepting other types. For example, FloatElementConverter also accepts IntegerElements. The default behavior can be adjusted with the fields accept_text, accept_int, accept_float, and accept_bool.
The following denotes what kind of StructureElements are accepted by default (they are defined in src/caoscrawler/converters.py):
BooleanElementConverter: bool, int
FloatElementConverter: int, float
TextElementConverter: text, bool, int, float
IntegerElementConverter: int
ListElementConverter: list
DictElementConverter: dict
YAMLFileConverter
A specialized Dict Converter for yaml files: Yaml files are opened and the contents are converted into dictionaries that can be further converted using the typical subtree converters of dict converter.
WARNING: Currently unfinished implementation.
JSONFileConverter
TableConverter
Table → DictElement
A generic converter (abstract) for files containing tables. Currently, there are two specialized implementations for XLSX files and CSV files.
All table converters generate a subtree of dicts, which in turn can be converted with DictElementConverters: For each row in the table the TableConverter generates a DictElement (structure element). The key of the element is the row number. The value of the element is a dict containing the mapping of column names to values of the respective cell.
Example:
subtree:
TABLE: # Any name for the table as a whole
type: CSVTableConverter
match: ^test_table.csv$
records:
(...) # Records edited for the whole table file
subtree:
ROW: # Any name for a data row in the table
type: DictElement
match_name: .*
match_value: .*
records:
(...) # Records edited for each row
subtree:
COLUMN: # Any name for a specific type of column in the table
type: FloatElement
match_name: measurement # Name of the column in the table file
match_value: (?P<column_value).*)
records:
(...) # Records edited for each cell
XLSXTableConverter
XLSX File → DictElement
CSVTableConverter
CSV File → DictElement
PropertiesFromDictConverter
The PropertiesFromDictConverter is
a specialization of the
DictElementConverter and offers
all its functionality. It is meant to operate on dictionaries (e.g.,
from reading in a json or a table file), the keys of which correspond
closely to properties in a LinkAhead datamodel. This is especially
handy in cases where properties may be added to the data model and
data sources that are not yet known when writing the cfood definition.
The converter definition of the
PropertiesFromDictConverter has an
additional required entry record_from_dict which specifies the
Record to which the properties extracted from the dict are attached
to. This Record is identified by its variable_name by which it can
be referred to further down the subtree. You can also use the name of
a Record that was specified earlier in the CFood definition in order
to extend it by the properties extracted from a dict. Let’s have a
look at a simple example. A CFood definition
PropertiesFromDictElement:
type: PropertiesFromDictElement
match: ".*"
record_from_dict:
variable_name: MyRec
parents:
- MyType1
- MyType2
applied to a dictionary
{
"name": "New name",
"a": 5,
"b": ["a", "b", "c"],
"author": {
"full_name": "Silvia Scientist"
}
}
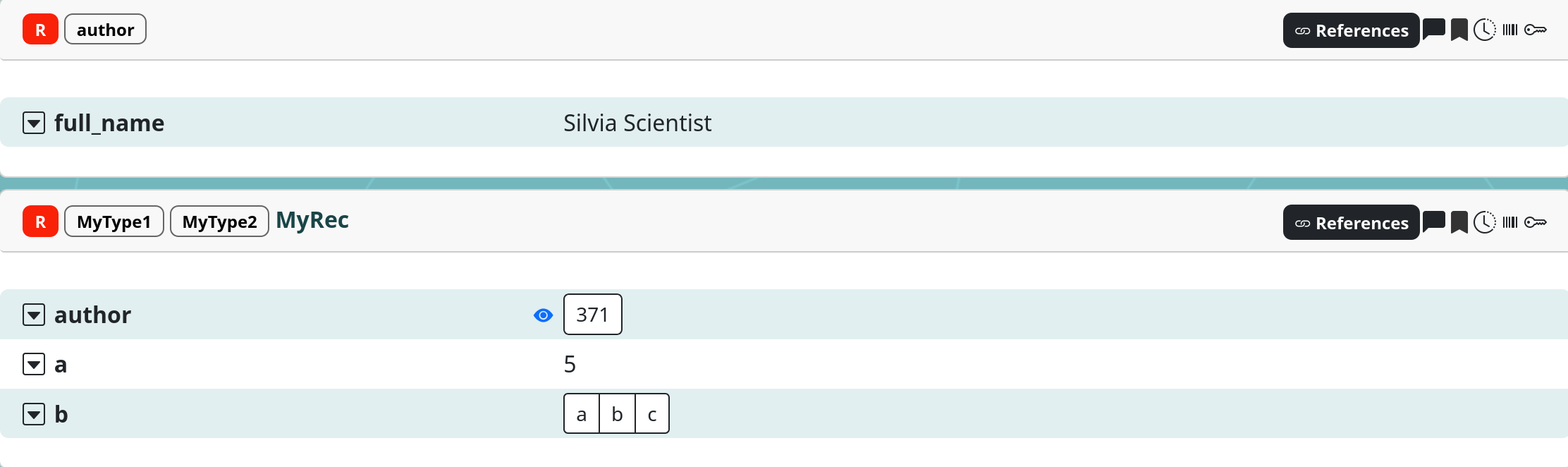
will create a Record New name with parents MyType1 and
MyType2. It has a scalar property a with value 5, a list
property b with values “a”, “b” and “c”, and an author
property which references an author with a full_name property
with value “Silvia Scientist”:
Note how the different dictionary keys are handled differently
depending on their types: scalar and list values are understood
automatically, and a dictionary-valued entry like author is
translated into a reference to an author Record automatically.
You can further specify how references are treated with an optional
references key in record_from_dict. Let’s assume that in the
above example, we have an author Property with datatype
Person in our data model. We could add this information by
extending the above example definition by
PropertiesFromDictElement:
type: PropertiesFromDictElement
match: ".*"
record_from_dict:
variable_name: MyRec
parents:
- MyType1
- MyType2
references:
author:
parents:
- Person
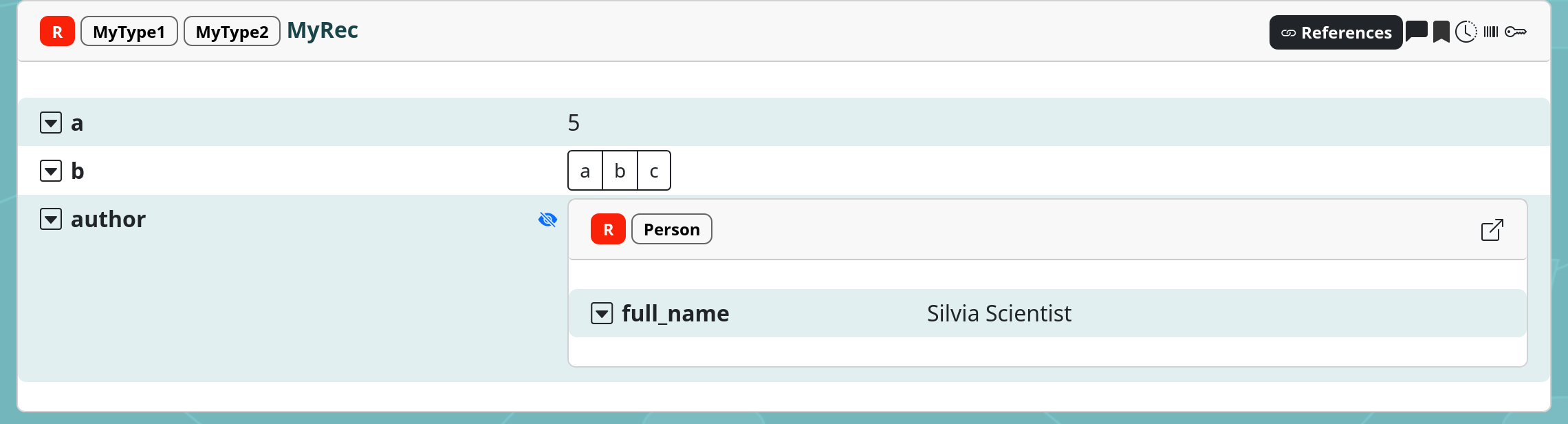
so that now, a Person record with a full_name property with
value “Silvia Scientist” is created as the value of the author
property:
For the time being, only the parents of the referenced record can be
set via this option. More complicated treatments can be implemented
via the referenced_record_callback (see below).
Properties can be blacklisted with the properties_blacklist
keyword, i.e., all keys listed under properties_blacklist will be
excluded from automated treatment. Since the
PropertiesFromDictConverter has
all the functionality of the
DictElementConverter, individual
properties can still be used in a subtree. Together with
properties_blacklist this can be used to add custom treatment to
specific properties by blacklisting them in record_from_dict and
then treating them in the subtree the same as you would do it in the
standard
DictElementConverter. Note that
the blacklisted keys are excluded on all levels of the dictionary,
i.e., also when they occur in a referenced entity.
For further customization, the
PropertiesFromDictConverter
can be used as a basis for custom converters
which can make use of its referenced_record_callback argument. The
referenced_record_callback can be a callable object which takes
exactly a Record as an argument and needs to return that Record after
doing whatever custom treatment is needed. Additionally, it is given
the RecordStore and the ValueStore in order to be able to
access the records and values that have already been defined from
within referenced_record_callback. Such a function might look the
following:
def my_callback(rec: db.Record, records: RecordStore, values: GeneralStore):
# do something with rec, possibly using other records or values from the stores...
rec.description = "This was updated in a callback"
return rec
It is applied to all Records that are created from the dictionary and
it can be used to, e.g., transform values of some properties, or add
special treatment to all Records of a specific
type. referenced_record_callback is applied after the
properties from the dictionary have been applied as explained above.
XML Converters
There are the following converters for XML content:
XMLFileConverter
This is a converter that loads an XML file and creates an XMLElement containing the root element of the XML tree. It can be matched in the subtree using the XMLTagConverter.
XMLTagConverter
The XMLTagConverter is a generic converter for XMLElements with the following main features:
It allows to match a combination of tag name, attribute names and text contents using the keys:
match_tag: regexp, default empty stringmatch_attrib: dictionary of key-regexps and value-regexp pairs. Each key matches an attribute name and the corresponding value matches its attribute value.match_text: regexp, default empty string
It allows to traverse the tree using XPath (using Python lxml’s xpath functions):
The key
xpathis used to set the xpath expression and has a default ofchild::*. Its default would generate just the list of sub nodes of the current node. The result of the xpath expression is used to generate structure elements as children. It furthermore uses the keystags_as_children,attribs_as_childrenandtext_as_childrento decide which information from the found nodes will be used as children:tags_as_children: (defaulttrue) For each xml tag element found by the xpath expression, generate one XMLTag structure element. Its name is the full path to the tag using the functiongetelementpathfromlxml.attribs_as_children: (defaultfalse) For each xml tag element found by the xpath expression, generate one XMLAttributeNode structure element for each of its attributes. The name of the respective attribute node has the form:<full path of the tag> @ <name of the attribute>Please note: Currently, there is no converter implemented that can match XMLAttributeNodes.text_as_children: (defaultfalse) For each xml tag element found by the xpath expression, generate one XMLTextNode structure element containing the text content of the tag element. Note that in case of multiple text elements, only the first one is added. The name of the respective attribute node has the form:<full path of the tag> /text()to the tag using the functiongetelementpathfromlxml. Please note: Currently, there is no converter implemented that can match XMLAttributeNodes.
Namespaces
The default is to take the namespace map from the current node and use
it in xpath queries. Because default namespaces cannot be handled by
xpath, it is possible to remap the default namespace using the key
default_namespace. The key nsmap can be used to define
additional nsmap entries.
XMLTextNodeConverter
In the future, this converter can be used to match XMLTextNodes that are generated by the XMLTagConverter.