Concepts
The CaosDB Crawler can handle any kind of hierarchical data structure. The typical use case is a directory tree that is traversed. We use the following terms/concepts to describe how the CaosDB Crawler works.
Basics
Structure Elements
The crawled hierarchical structure is represented by a tree of StructureElements. This tree is
generated on the fly by so called Converters which are defined in a yaml file (usually called
cfood.yml). This generated tree of StructureElements is a model of the existing data. For
example a tree of Python file objects (StructureElements) could correspond to a file system tree.
Relevant sources in:
Converters
Converters treat a StructureElement and during this process create a number of new StructureElements: the children of the initially treated StructureElement. Thus by treatment of existing StructureElements, Converters create a tree of StructureElements.
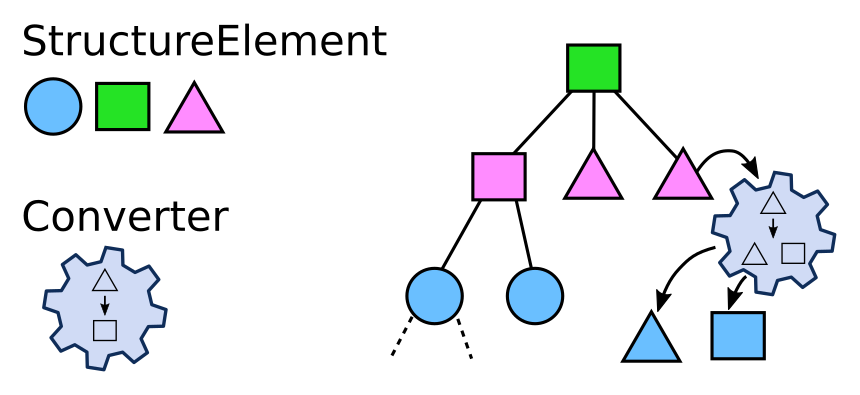
See the chapter Converters for details.
Relevant sources in:
Identifiables
An Identifiable of a Record is like the fingerprint of a Record.
The Identifiable contains the information that is used by the CaosDB Crawler to identify Records. For example, the CaosDB Crawler may create a query using the information contained in the Identifiable in order to check whether a Record exists in the CaosDB Server.
Suppose a certain experiment is at most done once per day, then the identifiable could consist of the RecordType “SomeExperiment” (as a parent) and the Property “date” with the respective value.
You can think of the properties that are used by the identifiable as a dictionary. For each property name there can be one value. However, this value can be a list such that the created query can look like “FIND RECORD ParamenterSet WITH a=5 AND a=6”. This is meaningful if there is a ParamenterSet with two Properties with the name ‘a’ (multi property) or if ‘a’ is a list containing at least the values 5 and 6.
When we use a reference Property in the identifiable, we effectively use the reference from the object to be identified pointing to some other object as an identifying attribute. We can also use references that point in the other direction, i.e. towards the object to be identified. An identifiable may denote one or more Entities that are referencing the object to be identified.
The path of a File object can serve as a Property that identifies files and similarly the name of Records can be used.
In the current implementation an identifiable can only use one RecordType even though the identified Records might have multiple Parents.
Relevant sources in
Registered Identifiables
A Registered Identifiable is the blue print for Identifiables. You can think of registered identifiables as identifiables without concrete values for properties. RegisteredIdentifiables are associated with RecordTypes and define of what information an identifiable for that RecordType exists. There can be multiple Registered Identifiables for one RecordType.
If identifiables shall contain references to the object to be identified, the Registered Identifiable must list the RecordTypes of the Entities that have those references. For example, the Registered Identifiable for the “Experiment” RecordType may contain the “date” Property and “Project” as the RecordType of an Entity that is referencing the object to be identified. Then if we have a structure of some Records at hand, we can check whether a Record with the parent “Project” is referencing the “Experiment” Record. If that is the case, this reference is part of the identifiable for the “Experiment” Record. Note, that if there are multiple Records with the appropriate parent (e.g. multiple “Project” Records in the above example) it will be required that all of them reference the object to be identified. You can also use the wildcard “*” as RecordType name in the configuration which will only require, that ANY Record references the Record at hand.
Identified Records
TODO
The Crawler
The crawler can be considered the main program doing the synchronization in basically two steps:
Based on a yaml-specification scan the file system (or other sources) and create a set of CaosDB Entities that are supposed to be inserted or updated in a CaosDB instance.
Compare the current state of the CaosDB instance with the set of CaosDB Entities created in step 1, taking into account the registered identifiables. Insert or update entites accordingly.
Relevant sources in:
Special Cases
Variable Precedence
Let’s assume the following situation
description:
type: DictTextElement
match_value: (?P<description>.*)
match_name: description
Making use of the $description variable could refer to two different variables created here: 1. The structure element path. 2. The value of the matched expression.
The matched expression does take precedence over the structure element path and shadows it.
Make sure, that if you want to be able to use the structure element path, to give unique names to the variables like:
description_text_block:
type: DictTextElement
match_value: (?P<description>.*)
match_name: description
Scopes
Example:
DicomFile:
type: SimpleDicomFile
match: (?P<filename>.*)\.dicom
records:
DicomRecord:
name: $filename
subtree: # header of dicom file
PatientID:
type: DicomHeaderElement
match_name: PatientName
match_value: (?P<patient>.*)
records:
Patient:
name: $patient
dicom_name: $filename # $filename is in same scope!
ExperimentFile:
type: MarkdownFile
match: ^readme.md$
records:
Experiment:
dicom_name: $filename # does NOT work, because $filename is out of scope!
# can variables be used within regexp?
File Objects
TODO
Caching
The Crawler uses the cached library function cached_get_entity_by. The cache is cleared
automatically when the Crawler does updates, but if you ran the same Python process indefinitely,
the Crawler would not see changes in LinkAhead due to the cache. Thus, please make sure to clear the
cache if you create long running Python processes.