Converters
Converters treat a StructureElement and during this process create a number of new StructureElements: the children of the initially treated StructureElement. Thus by treatment of existing StructureElements, Converters create a tree of StructureElements.
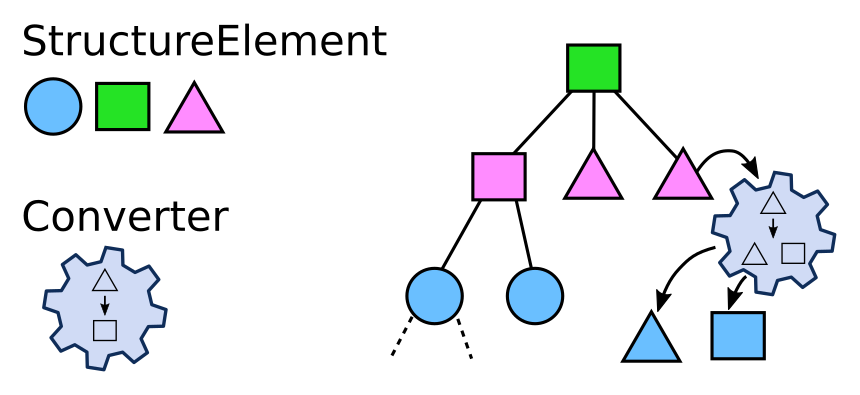
The cfood.yml definition also describes which
Converters shall be used to treat the generated child StructureElements. The
definition therefore itself also defines a tree.
Each StructureElement in the tree has a set of properties, organized as
key-value pairs.
Some of those properties are specified by the type of StructureElement. For example,
a file could have the file name as property: 'filename': myfile.dat.
Converters may define additional functions that create further values. For
example, a regular expression could be used to get a date from a file name.
A converter is defined via a yml file or part of it. The definition states what kind of StructureElement it treats (typically one). Also, it defines how children of the current StructureElement are created and what Converters shall be used to treat those.
The yaml definition may look like this:
TODO: outdated, see cfood-schema.yml
<NodeName>:
type: <ConverterName>
match: ".*"
records:
Experiment1:
parents:
- Experiment
- Blablabla
date: $DATUM
(...)
Experiment2:
parents:
- Experiment
subtree:
(...)
The <NodeName> is a description of what it represents (e.g. ‘experiment-folder’) and is used as identifier.
<type> selects the converter that is going to be matched against the current structure
element. If the structure element matches (this is a combination of a typecheck and a detailed
match, see Converter for details) the converter is used
to generate records (see create_records()) and to possibly process a subtree, as defined by the function caoscrawler.converters.create_children().
records is a dict of definitions that define the semantic structure (see details below).
subtree makes the yaml recursive: It contains a list of new Converter definitions, which work on the StructureElements that are returned by the current Converter.
Transform Functions
Often the situation arises, that you cannot use a value as it is found. Maybe a value should be increased by an offset or a string should be split into a list of pieces. In order to allow such simple conversions, transform functions can be named in the converter definition that are then applied to the respective variables when the converter is executed.
<NodeName>:
type: <ConverterName>
match: ".*"
transform:
<TransformNodeName>:
in: $<in_var_name>
out: $<out_var_name>
functions:
- <func_name>: # name of the function to be applied
<func_arg1>: <func_arg1_value> # key value pairs that are passed as parameters
<func_arg2>: <func_arg2_value>
# ...
An example that splits the variable a and puts the generated list in b is the following:
Experiment:
type: Dict
match: ".*"
transform:
param_split:
in: $a
out: $b
functions:
- split: # split is a function that is defined by default
marker: "|" # its only parameter is the marker that is used to split the string
records:
Report:
tags: $b
This splits the string in ‘$a’ and stores the resulting list in ‘$b’. This is here used to add a list valued property to the Report Record.
There are a number of transform functions that are defined by default (see
src/caoscrawler/default_transformers.yml). You can define custom transform functions by adding
them to the cfood definition (see CFood Documentation).
Standard Converters
These are the standard converters that exist in a default installation. For writing and applying custom converters, see below.
Directory Converter
The Directory Converter creates StructureElements for each File and Directory inside the current Directory. You can match a regular expression against the directory name using the ‘match’ key.
Simple File Converter
The Simple File Converter does not create any children and is usually used if a file shall be used as it is and be inserted and referenced by other entities.
Markdown File Converter
Reads a YAML header from Markdown files (if such a header exists) and creates children elements according to the structure of the header.
DictElement Converter
DictElement → StructureElement
Creates a child StructureElement for each key in the dictionary.
Typical Subtree converters
The following StructureElement types are typically created by the DictElement converter:
BooleanElement
FloatElement
TextElement
IntegerElement
ListElement
DictElement
Scalar Value Converters
BooleanElementConverter, FloatElementConverter, TextElementConverter, and IntegerElementConverter behave very similarly.
These converters expect match_name and match_value in their definition which allow to match the key and the value, respectively.
Note that there are defaults for accepting other types. For example, FloatElementConverter also accepts IntegerElements. The default behavior can be adjusted with the fields accept_text, accept_int, accept_float, and accept_bool.
The following denotes what kind of StructureElements are accepted by default (they are defined in src/caoscrawler/converters.py):
BooleanElementConverter: bool, int
FloatElementConverter: int, float
TextElementConverter: text, bool, int, float
IntegerElementConverter: int
ListElementConverter: list
DictElementConverter: dict
YAMLFileConverter
A specialized Dict Converter for yaml files: Yaml files are opened and the contents are converted into dictionaries that can be further converted using the typical subtree converters of dict converter.
WARNING: Currently unfinished implementation.
JSONFileConverter
TableConverter
Table → DictElement
A generic converter (abstract) for files containing tables. Currently, there are two specialized implementations for XLSX files and CSV files.
All table converters generate a subtree of dicts, which in turn can be converted with DictElementConverters: For each row in the table the TableConverter generates a DictElement (structure element). The key of the element is the row number. The value of the element is a dict containing the mapping of column names to values of the respective cell.
Example:
subtree:
TABLE: # Any name for the table as a whole
type: CSVTableConverter
match: ^test_table.csv$
records:
(...) # Records edited for the whole table file
subtree:
ROW: # Any name for a data row in the table
type: DictElement
match_name: .*
match_value: .*
records:
(...) # Records edited for each row
subtree:
COLUMN: # Any name for a specific type of column in the table
type: FloatElement
match_name: measurement # Name of the column in the table file
match_value: (?P<column_value).*)
records:
(...) # Records edited for each cell
XLSXTableConverter
XLSX File → DictElement
CSVTableConverter
CSV File → DictElement
Further converters
More converters, together with cfood definitions and examples can be found in the LinkAhead Crawler Extensions Subgroup on gitlab. In the following, we list converters that are shipped with the crawler library itself but are not part of the set of standard converters and may require this library to be installed with additional optional dependencies.
HDF5 Converters
For treating HDF5 Files, there are in total
four individual converters corresponding to the internal structure of HDF5 files:
the H5FileConverter which opens the file itself and creates further
structure elements from HDF5 groups, datasets, and included multi-dimensional
arrays that are in turn treated by the H5GroupConverter, the
H5DatasetConverter, and the H5NdarrayConverter, respectively. You
need to install the LinkAhead crawler with its optional h5crawler dependency
for using these converters.
The basic idea when crawling HDF5 files is to treat them very similar to
dictionaries in which the attributes on root,
group, or dataset level are essentially treated like BooleanElement,
TextElement, FloatElement, and IntegerElement in a dictionary: They
are appended as children and can be accessed via the subtree. The file
itself and the groups within may contain further groups and datasets, which can
have their own attributes, subgroups, and datasets, very much like
DictElements within a dictionary. The main difference to any other
dictionary type is the presence of multi-dimensional arrays within HDF5
datasets. Since LinkAhead doesn’t have any datatype corresponding to these, and
since it isn’t desirable to store these arrays directly within LinkAhead for
reasons of performance and of searchability, we wrap them within a specific
Record as explained below, together with more
metadata and their internal path within the HDF5 file. Users can thus query for
datasets and their arrays according to their metadata within LinkAhead and then
use the internal path information to access the dataset within the file
directly. The type of this record and the property for storing the internal path
need to be reflected in the datamodel. Using the default names, you would need a
datamodel like
H5Ndarray:
obligatory_properties:
internal_hdf5-path:
datatype: TEXT
although the names of both property and record type can be configured within the cfood definition.
A simple example of a cfood definition for HDF5 files can be found in the unit tests and shows how the individual converters are used in order to crawl a simple example file containing groups, subgroups, and datasets, together with their respective attributes.
H5FileConverter
This is an extension of the
SimpleFileConverter class. It opens the HDF5
file and creates children for any contained group or dataset. Additionally, the
root-level attributes of the HDF5 file are accessible as children.
H5GroupConverter
This is an extension of the
DictElementConverter class. Children are
created for all subgroups and datasets in this HDF5 group. Additionally, the
group-level attributes are accessible as children.
H5DatasetConverter
This is an extension of the
DictElementConverter class. Most
importantly, it stores the array data in HDF5 dataset into
H5NdarrayElement which is added to its
children, as well as the dataset attributes.
H5NdarrayConverter
This converter creates a wrapper record for the contained dataset. The name of
this record needs to be specified in the cfood definition of this converter via
the recordname option. The RecordType of this record can be configured with
the array_recordtype_name option and defaults to H5Ndarray. Via the
given recordname, this record can be used within the cfood. Most
importantly, this record stores the internal path of this array within the HDF5
file in a text property, the name of which can be configured with the
internal_path_property_name option which defaults to internal_hdf5_path.
Custom Converters
As mentioned before it is possible to create custom converters. These custom converters can be used to integrate arbitrary data extraction and ETL capabilities into the LinkAhead crawler and make these extensions available to any yaml specification.
Tell the crawler about a custom converter
To use a custom crawler, it must be defined in the Converters section of the CFood yaml file.
The basic syntax for adding a custom converter to a definition file is:
Converters:
<NameOfTheConverterInYamlFile>:
package: <python>.<module>.<name>
converter: <PythonClassName>
The Converters section can be either put into the first or the second document of the cfood yaml file. It can be also part of a single-document yaml cfood file. Please refer to the cfood documentation for more details.
Details:
<NameOfTheConverterInYamlFile>: This is the name of the converter as it is going to be used in the present yaml file.
<python>.<module>.<name>: The name of the module where the converter class resides.
<PythonClassName>: Within this specified module there must be a class inheriting from base class
caoscrawler.converters.Converter.
Implementing a custom converter
Converters inherit from the Converter class.
The following methods are abstract and need to be overwritten by your custom converter to make it work:
create_children():Return a list of child StructureElement objects.
Example
In the following, we will explain the process of adding a custom converter to a yaml file using a SourceResolver that is able to attach a source element to another entity.
Note: This example might become a standard crawler soon, as part of the scifolder specification. See https://doi.org/10.3390/data5020043 for details. In this documentation example we will, therefore, add it to a package called “scifolder”.
First we will create our package and module structure, which might be:
scifolder_package/
README.md
setup.cfg
setup.py
Makefile
tox.ini
src/
scifolder/
__init__.py
converters/
__init__.py
sources.py # <- the actual file containing
# the converter class
doc/
unittests/
Now we need to create a class called “SourceResolver” in the file “sources.py”. In this - more advanced - example, we will not inherit our converter directly from Converter, but use TextElementConverter. The latter already implements match() and typecheck(), so only an implementation for create_children() has to be provided by us.
Furthermore we will customize the method create_records() that allows us to specify a more complex record generation procedure than provided in the standard implementation. One specific limitation of the standard implementation is, that only a fixed
number of records can be generated by the yaml definition. So for any applications - like here - that require an arbitrary number of records to be created, a customized implementation of create_records() is recommended.
In this context it is recommended to make use of the function caoscrawler.converters.create_records() that implements creation of record objects from python dictionaries of the same structure
that would be given using a yaml definition (see next section below).
import re
from caoscrawler.stores import GeneralStore, RecordStore
from caoscrawler.converters import TextElementConverter, create_records
from caoscrawler.structure_elements import StructureElement, TextElement
class SourceResolver(TextElementConverter):
"""
This resolver uses a source list element (e.g. from the markdown readme file)
to link sources correctly.
"""
def __init__(self, definition: dict, name: str,
converter_registry: dict):
"""
Initialize a new directory converter.
"""
super().__init__(definition, name, converter_registry)
def create_children(self, generalStore: GeneralStore,
element: StructureElement):
# The source resolver does not create children:
return []
def create_records(self, values: GeneralStore,
records: RecordStore,
element: StructureElement,
file_path_prefix):
if not isinstance(element, TextElement):
raise RuntimeError()
# This function must return a list containing tuples, each one for a modified
# property: (name_of_entity, name_of_property)
keys_modified = []
# This is the name of the entity where the source is going to be attached:
attach_to_scientific_activity = self.definition["scientific_activity"]
rec = records[attach_to_scientific_activity]
# The "source" is a path to a source project, so it should have the form:
# /<Category>/<project>/<scientific_activity>/
# obtain these information from the structure element:
val = element.value
regexp = (r'/(?P<category>(SimulationData)|(ExperimentalData)|(DataAnalysis))'
'/(?P<project_date>.*?)_(?P<project_identifier>.*)'
'/(?P<date>[0-9]{4,4}-[0-9]{2,2}-[0-9]{2,2})(_(?P<identifier>.*))?/')
res = re.match(regexp, val)
if res is None:
raise RuntimeError("Source cannot be parsed correctly.")
# Mapping of categories on the file system to corresponding record types in CaosDB:
cat_map = {
"SimulationData": "Simulation",
"ExperimentalData": "Experiment",
"DataAnalysis": "DataAnalysis"}
linkrt = cat_map[res.group("category")]
keys_modified.extend(create_records(values, records, {
"Project": {
"date": res.group("project_date"),
"identifier": res.group("project_identifier"),
},
linkrt: {
"date": res.group("date"),
"identifier": res.group("identifier"),
"project": "$Project"
},
attach_to_scientific_activity: {
"sources": "+$" + linkrt
}}, file_path_prefix))
# Process the records section of the yaml definition:
keys_modified.extend(
super().create_records(values, records, element, file_path_prefix))
# The create_records function must return the modified keys to make it compatible
# to the crawler functions:
return keys_modified
If the recommended (python) package structure is used, the package containing the converter definition can just be installed using pip install . or pip install -e . from the scifolder_package directory.
The following yaml block will register the converter in a yaml file:
Converters:
SourceResolver:
package: scifolder.converters.sources
converter: SourceResolver
Using the create_records API function
The function caoscrawler.converters.create_records() was already mentioned above and it is
the recommended way to create new records from custom converters. Let’s have a look at the
function signature:
def create_records(values: GeneralStore, # <- pass the current variables store here
records: RecordStore, # <- pass the current store of CaosDB records here
def_records: dict): # <- This is the actual definition of new records!
def_records is the actual definition of new records according to the yaml cfood specification (work in progress, in the docs). Essentially you can do everything here, that you could do in the yaml document as well, but using python source code.
Let’s have a look at a few examples:
DirConverter:
type: Directory
match: (?P<dir_name>.*)
records:
Experiment:
identifier: $dir_name
This block will just create a new record with parent Experiment and one property identifier with a value derived from the matching regular expression.
Let’s formulate that using create_records:
dir_name = "directory name"
record_def = {
"Experiment": {
"identifier": dir_name
}
}
keys_modified = create_records(values, records,
record_def)
The dir_name is set explicitely here, everything else is identical to the yaml statements.
The role of keys_modified
You probably have noticed already, that caoscrawler.converters.create_records() returns
keys_modified which is a list of tuples. Each element of keys_modified has two elements:
Element 0 is the name of the record that is modified (as used in the record store records).
Element 1 is the name of the property that is modified.
It is important, that the correct list of modified keys is returned by
create_records() to make the crawler process work.
So, a sketch of a typical implementation within a custom converter could look like this:
def create_records(self, values: GeneralStore,
records: RecordStore,
element: StructureElement,
file_path_prefix: str):
# Modify some records:
record_def = {
# ...
}
keys_modified = create_records(values, records,
record_def)
# You can of course do it multiple times:
keys_modified.extend(create_records(values, records,
record_def))
# You can also process the records section of the yaml definition:
keys_modified.extend(
super().create_records(values, records, element, file_path_prefix))
# This essentially allows users of your converter to customize the creation of records
# by providing a custom "records" section additionally to the modifications provided
# in this implementation of the Converter.
# Important: Return the list of modified keys!
return keys_modified
More complex example
Let’s have a look at a more complex examples, defining multiple records:
DirConverter:
type: Directory
match: (?P<dir_name>.*)
records:
Project:
identifier: project_name
Experiment:
identifier: $dir_name
Project: $Project
ProjectGroup:
projects: +$Project
This block will create two new Records:
A project with a constant identifier
An experiment with an identifier, derived from a regular expression and a reference to the new project.
Furthermore a Record ProjectGroup will be edited (its initial definition is not given in the yaml block): The project that was just created will be added as a list element to the property projects.
Let’s formulate that using create_records (again, dir_name is constant here):
dir_name = "directory name"
record_def = {
"Project": {
"identifier": "project_name",
}
"Experiment": {
"identifier": dir_name,
"Project": "$Project",
}
"ProjectGroup": {
"projects": "+$Project",
}
}
keys_modified = create_records(values, records,
record_def)
Debugging
You can add the key debug_match to the definition of a Converter in order to create debugging output for the match step. The following snippet illustrates this:
DirConverter:
type: Directory
match: (?P<dir_name>.*)
debug_match: True
records:
Project:
identifier: project_name
Whenever this Converter tries to match a StructureElement, it logs what was tried to macht against what and what the result was.