Creating and modifying LinkAhead datamodels
LinkAhead datamodels are essentially defined by the RecordTypes and Properties in one LinkAhead instance. This tutorial will explain how to create complex, use-case specific datamodels and what best practices there are to modify them.
Note
This tutorial is intended for users that are already fairly familiar with the basics of data models in LinkAhead (see the general explanation and the basic tutorial in the LinkAhead server documentation for an introduction).
Creating an initial datamodel
When initially creating a new datamodel, it is important to keep in mind that the designing of a datamodel is an iterative process. In case of uncertainties, it is usually a good idea to just start with a generic model and refine it while already using it to manage data in LinkAhead – after all, that’s what LinkAhead’s flexibility is for.
Prerequisites
Before defining a data model, there are a few questions that you should ask yourself, your work group, the members of your institution, etc.
What (meta-)data is recorded? What might be added in the future? There is no need to over-engineer a datamodel to cover cases that will never come to pass.
What queries might users ask? What properties of the data might be used to filter results? The datamodel needs to cover all types and properties necessary for these queries.
How will different entries be related? While it doesn’t need to be complete, drawing (a sketch of) an entity relationship diagram might be helpful to see which RecordTypes will be needed, how they should reference each other, and how they should inherit from each other.
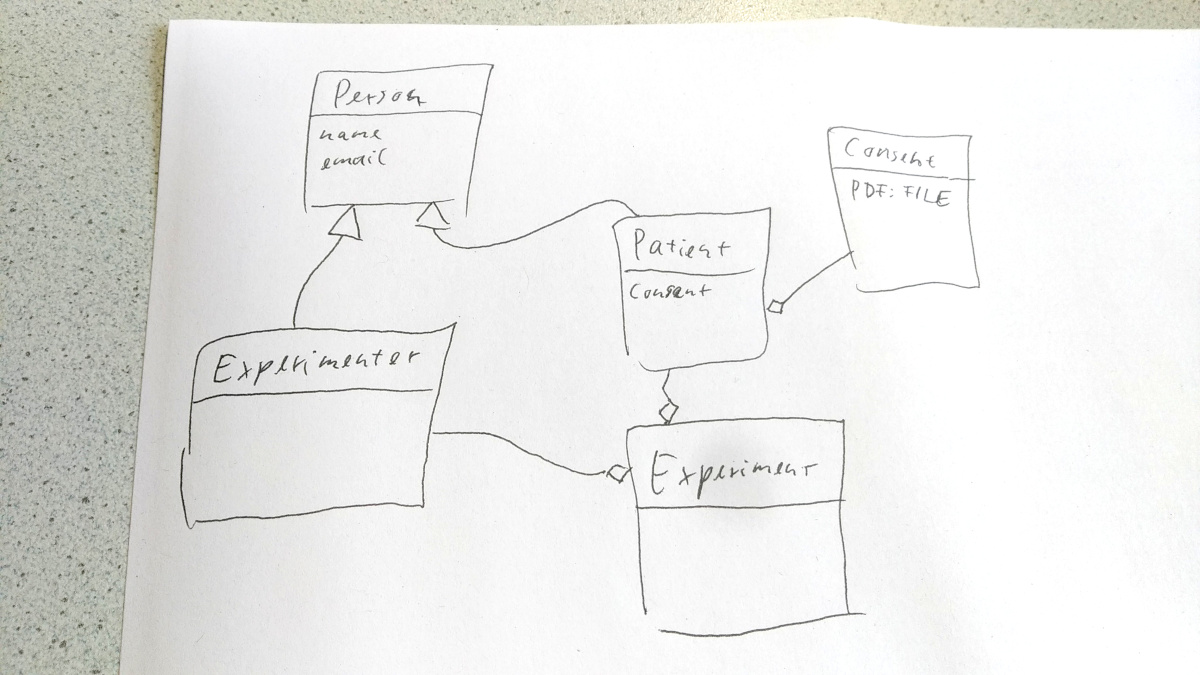
A simple sketch of a datamodel may be sufficient for the beginning.
Some thought can already be put into datatypes of properties, namely which
properties should have primitive datatypes (BOOLEAN, INTEGER, FLOAT,
or TEXT) and which should be references to other objects. For example, an
author could be either given simply by a TEXT containing the author’s full
name, or by referencing a Record of type, e.g., person which has properties for
family name, given name, email address, …
YAML and json schema specifications
Especially for the initial insertion of datamodels, the LinkAhead Advanced User
tools offer parser modules for YAML
and json schema
specifications. The YAML specification is the more mature one and supports
features like inheritances that the json schema specification does not (yet, see
the development issue), so
in most cases, the former is the natural choice when designing a new data
model. The json schema specification however can still be handy if you already
know that you will use json schema to build web forms or validate user input later on. It
is also possible to combine both ways, as you can see in this example by the Leibniz Centre for
Tropical Marine Research: you can simply use entities defined in the json schema
specification within the YAML specification via the extern keyword.
In both cases, the specifications can be loaded and synchronized with a
LinkAhead server by using the models.parser
module from the LinkAhead advanced user tools, specifically the
parse_model_from_yaml and parse_model_from_string functions therein.
In case of the yaml definition, you can also invoke the loading and synchronization from the command line using
python -m caosadvancedtools.models.parser --sync data_model.yaml
Enums
LinkAhead does not have an explicit enum type (yet – this may change in the future). However, for enum use cases it has proven useful to define a RecordType for the desired enum and separate Records of this type as enum values. This is also the default behavior of the json schema parser when encountering enums in the json schema specification. For example,
{
"type": "object",
"title": "Dataset",
"properties": {
"keyword": {
"enum": ["Experiment", "Numerical simulation", "Data analysis"]
}
}
}
creates a Keyword RecordType and three Keyword Records with names
Experiment, Numerical simulation, and Data analysis. Any other
Record, that is supposed to have an enum typed keyword property, can then simply
reference one of the existing Keyword Records. Depending on your use case,
you might want to restrict the USE:AS_PARENT entity permission
of the Keyword RecordType to prevent unprivileged users from creating
Records of this type (see below). Note that the YAML parser does not support the
automatic creation of enum-like Records yet.
Remarks on permissions
When creating a datamodel it usually is beneficial to think about who is allowed to extend or change it in the future. This is generally done using role and entity permissions. Often however, there is something like a “core data model” that some functionality might depend on (web forms, a crawler, …), and that should be changed only if really necessary. In LinkAhead Pylib’s documentation there is a documented example which prevents a subset of the datamodel from being edited even by data curators and explicitly requires administration permissions, while all other entities can be created, updated, or deleted by curators at will.
Modify an existing datamodel
LinkAhead provides the flexibility to change datamodels in the running system without necessarily having to migrate old data (see below in case you do need to migrate after all). Nevertheless, especially for substantial changes, it is crucial to make backups and, if possible, test changes on a development instance first. Of course, small changes can be performed using the WebUI’s edit mode, for larger changes or to make the changes more reproducible and document them, a programmatic approach is usually desirable, either via the above datamodel specifications or a custom script.
Using the datamodel specifications
The aforementioned YAML and json schema specifications can be used to update
existing entities, too. Some care has to be taken when using them to change
datamodels, though. In case of a YAML specification, existing entities can be
used without redefining them using the extern keyword (not possible in the
json schema specification as of now). Otherwise, if in the specification an
entity with the same name as an existing one is defined, it is considered a
redefinition of the existing one and an update of the existing entity will be
attempted upon synchronization. In most of the cases, this behavior is
desirable, but there may be corner cases (e.g., name duplicates) in which it is
not. Most notably, these updates can’t be used to remove properties. I.e., a
RecordType to be updated can only obtain new properties but the synchronization
process will never remove any. In the same way, no existing entities will be
deleted even if they are not part of the specification anymore.
Using custom scripts
For cases like deletions of properties from a RecordType, deletions of entities from the system, or other more complex cases, possibly in combination with data migrations (see below), custom scripts can be used. These offer the full capabilities of, e.g., the Python client, so changing any number of entities in any way (that the user is allowed to) is possible. When developing such scripts, it is crucial to test them carefully, ideally against a development instance and not against a productive system.
Some general best practices can be followed here.
Even after careful testing, write your scripts in a way that they don’t leave the database in a broken state if an error occurs halfway through its execution. E.g., perform sanity checks and verify that transactions can be performed before actually inserting/updating/deleting anything.
Keep track of what scripts have been applied already at what time. In case you should ever have to restore a backup, you will want to know which changes to the datamodel (and possibly, which migrations) need to be applied.
Write your scripts in such a way, that they don’t do any harm if accidentally executed twice. This is especially true if you need to insert entities with the unique=False flag, i.e., omitting the unique names check.
Best practices for migrating existing data
With LinkAhead, migrating is often not necessary since old and new data (i.e.,
data that was created before and after a significant change to the data model)
can coexist and be searched for collectively as long as they are
compatible. Sometimes it is desirable to migrate old data, e.g., an author
property that changed from datatype TEXT to a reference to a person record:
You might want to create new person records with names stemming from the old
TEXT values.
There is currently no one best practice for doing these migrations, and they usually require the writing of custom scripts. There will be a more formalized way of changing datamodels and migrating data in the future; it is part of an ongoing discussion in the corresponding GitLab issue. There will be standard ways to define which (part of a) datamodel is present, and checking which migrations can and should be applied.